训练类神经网络一般步骤
什么是机器学习?
一句话概括:机器学习就是让机器具备找一个函数的能力。
目前机器学习应用的最多的3个问题,分别是Regression(回归)、Classification(分类)和Structured Learing(结构学习)
Regression:要找的函数,他的输出是一个数值
Classification:函数的输出,就是从设定好的选项裡面,选择一个当作输出
Structured Learning:机器产生有结构的东西的问题——学会创造
机器学习的一般步骤
刚刚说了,机器学习实际上就是找到一个函数,能达成我们的目标,拿语言识别举例,我们要找的函数,就是输入为一段音频,输出为这个音频的文字版。而寻找这个函数一般需要3个步骤:(这里以预测youtube的观看人数为例,classification其实同理,即用[1,0,0,0,0,0]这样的one-hot vector表示输出,具体参考https://www.bilibili.com/video/BV1Wv411h7kN?spm_id_from=333.788.videopod.episodes&vd_source=c06338b0283c611d7a47c62b0ed23dfa&p=22)
1.Function with Unknown Parameters(写出一个带有未知参数的函式)

$y$是我们准备要预测的东西,我们准备要预测的人
$x_1$是这个频道前一天总共观看的人数,跟y一样都是数值,
b跟w是未知的参数,它是准备要透过资料去找出来的,我们还不知道w跟b应该是多少
猜测:未来点阅次数的函式F,是前一天的点阅次数,乘上w 再加上b
⇒猜测往往就来自于对这个问题本质上的了解⇒Domain knowledge
名词定义:
**Feature:**Function里面我们已知的信息【 $x_1$】
**Weight:**未知参数,跟feature直接相乘
**Bias:**未知参数,直接相加
2.Define Loss from Training Data

Loss也是一个Function,它的输入,是Model里面的参数
这里:输入为w,b
物理意义:Function输出的值代表,现在如果我们把这一组未知的参数,设定某一个数值的时候,这笔数值好还是不好。
L越大,代表一组参数越不好,这个大L越小,代表现在这一组参数越好
计算方法:求取估测的值跟实际的值(Label) 之间的差距
- MAE(mean absolute error)
- MSE(mean square error)
- Cross-entropy:计算概率分布之间的差距
Error Surface:试了不同的参数,然后计算它的Loss,画出来的等高线图
3.Optimization(优化)
找到能让损失函数值最小的参数。
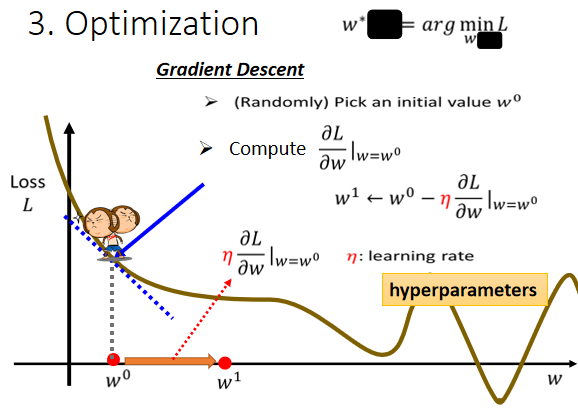
具体方法:Gradient Descent(梯度下降)
随机选取初始值 $w_0$
计算在 $w=w_0$的时候,w这个参数对loss的微分是多少
根据微分(梯度)的方向,改变参数的值
改变的大小取决于:
- 斜率的大小
- 学习率的大小(超参数)
train不起来怎么办?
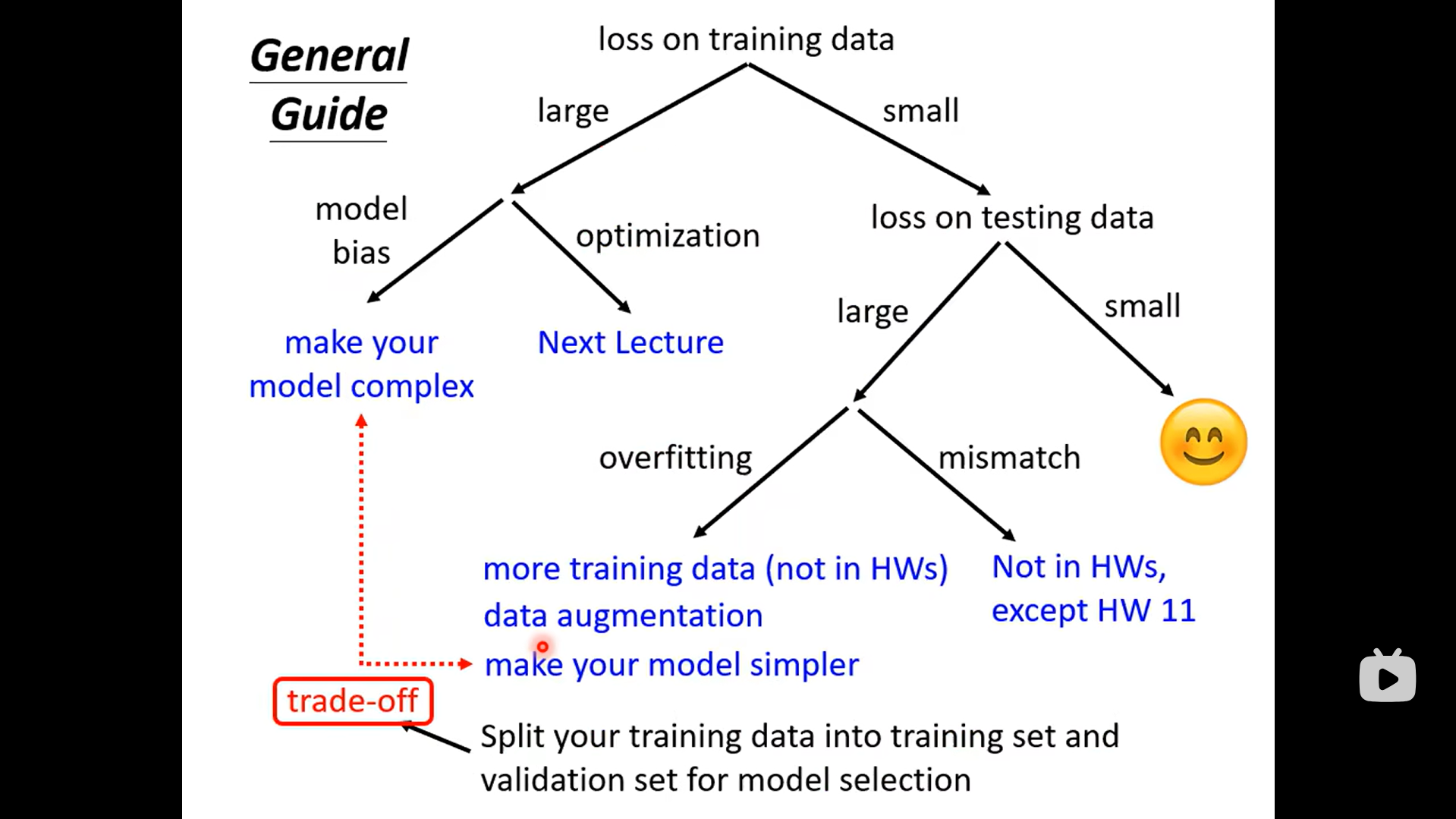
1. 分析在训练数据上的Loss
首先分析在训练数据上的Loss,如果training data的loss都很大,那么testing data的loss当然大。
(1)Model Bias
所有的function集合起来,得到一个function的set.但是这个function的set太小了,没有包含任何一个function,可以让我们的loss变低⇒可以让loss变低的function,不在model可以描述的范围内。
⇒解决方法:重新设计一个Model,一个更复杂的、更有弹性的、有未知参数的、需要更多features的function(还是以预测youtube为例,可以选前七天甚至前一个月的数据作为feature,其次,可以改变model architecture,即多叠几层,或者增加Relu的数量等等)
(2)Optimization
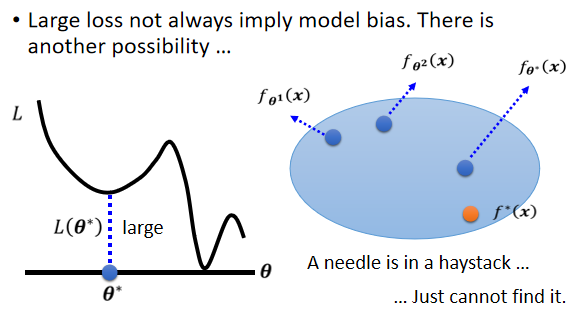
可能会卡在local minima(局部极小值/鞍点)的地方,没有办法找到一个真的可以让loss很低的参数。(例如卡在$\theta$*,此时gradient也为0,因此不会到真正的最低点)
(3)如何区分两种情况?
Start from shallower networks (or other models), which are easier to train.
看到一个你从来没有做过的问题,也许你可以先跑一些比较小的,比较浅的network,或甚至用一些,不是deep learning的方法⇒**比较容易做Optimize的,**它们比较不会有optimization失败的问题
If deeper networks do not obtain smaller loss on training data, then there is optimization issue.
如果你发现你深的model,跟浅的model比起来,深的model明明弹性比较大,但loss却没有办法比浅的model压得更低,那就代表说你的optimization有问题
2.分析测试数据上的Loss
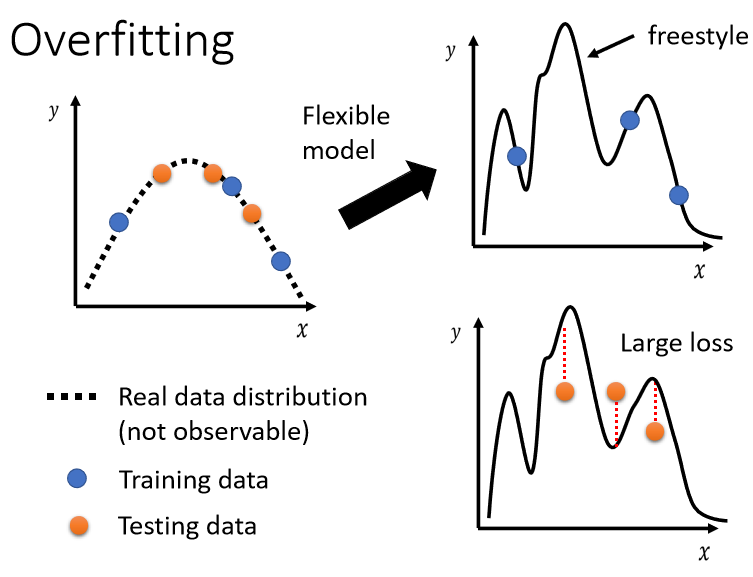
Overfitting:training的loss小,testing的loss大,这个有可能是overfitting
如果你的model它的自由度很大的话,它可以产生非常奇怪的曲线,导致训练集上的结果好,但是测试集上的loss很大,如图:
解决:
(1)增加训练集
虽然你的model它的弹性可能很大,但是因为数据样本非常非常的多,它就可以限制住
Data Augmentation(数据增强):用一些你对于这个问题的理解,从已有的数据中,自己创造出新的数据⇒注意合理性
(2)限制模型,使之不要有那么大弹性
- 给它比较少的参数(比如神经元的数目);模型共用参数
- 使用比较少的features(feature selecting,利用domain knowledge筛选你认为有用的feature,去除没用的knowledge)
- Early Stopping
- Regularization
- Dropout
3.如何选出有较低testing-loss的模型?
Cross Validation
- 把Training的资料分成两半,一部分叫作Training Set,一部分是Validation Set
- 在Validation Set上面,去衡量它们的分数,你根据Validation Set上面的分数,去挑选结果,不要管在public testing set上的结果,避免overfiting
参考链接: